就在昨天(3 月 25 日),谷歌发布了一项直接引起美光、SK 海力士等存储巨头股价下跌的技术——TurboQuant。
美光昨晚就跌超 4%,闪迪一度大跌 6.5% ,SK 海力士在韩股今天开盘后也很快下跌 3%。

不是新模型,也不是新产品,TurboQuant 是谷歌最新推出的一种推理优化技术,更准确一点地说,是 AI 推理阶段的「内存压缩算法」。按照官方基于开源模型的测试,TurboQuant 至少能将 KV Cache(键值缓存)的内存需求:
降低 6 倍。
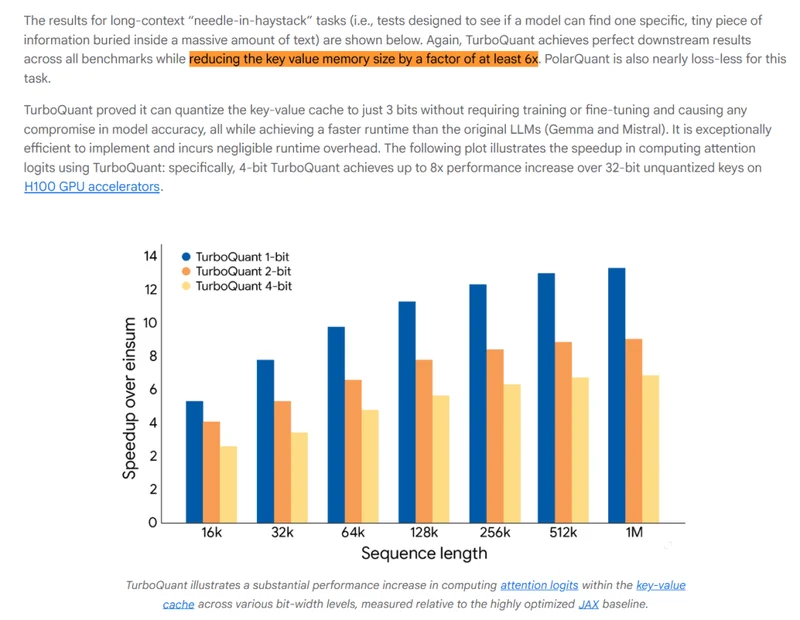
这里需要解释一下,在推理阶段(和 AI 对话的时候),模型需要不断记录上下文,这部分就叫「KV Cache」,你也可以将它理解为 AI 的短期记忆。正常情况下,你和 AI 聊得越多,它记得越多,占用的内存也就越大。
而 TurboQuant 的目标用一句话概括就是:把 AI 的「记忆」压缩,但尽量做到无损,不让它变笨。
实际上,TurboQuant 关键做了两件事,一是通过 PolarQuant 的方法尽可能把原本高精度的数据(比如 32 位)无损压缩到 3bit 级别;二是通过 QJL 算法把压缩带来的误差修正。
先不论技术上的实现,如果真的能在更广泛的模型上做到「无损压缩」,TurboQuant 毫无疑问会成为一项极其关键的技术。毕竟,内存对于 AI 来说,真就是一个瓶颈,一个房间里的大象。

首先是推理成本。AI 推理最贵的就是算力和内存,如何如果这一块能压缩到原本的六分之一,很多原本成本很高的 AI 服务就会变得更容易普及。
其次是更多的计算设备。现在很多 AI 只能跑在云端,很大原因就是本地设备带不动。但如果内存需求下降,手机、车机甚至一些边缘设备,理论上都有机会运行更强的模型,在实际应用上会更加灵活。
再往前一步看,甚至会影响我们怎么用 AI。
现在很多模型其实不是「不会」,而是「记不住」,上下文一长,就开始丢信息、答非所问。尤其是以 OpenClaw(龙虾)为代表的一系列 Agent 产品,更加依赖长上下文。

如果 TurboQuant 能让模型在有限资源下记住更多内容,那长对话、多步骤任务执行这些场景,体验可能会明显提升。
当然,也需要冷静一点看。
目前 TurboQuant 距离大规模落地还有距离,还只在 Gemma 与 Mistral 开源模型上进行部分测试 ,能不能在 Gemini 以及其他模型上实现相近的效果,还不得而知。
另一方面,它改进的是推理过程的内存占用,并没有改变模型本身的能力,也无法降低训练成本。