在这个所有科技巨头都在为英伟达的高端GPU抢破头的时代,一家成立不到三年的多伦多小厂Taalas,突然朝着整个行业扔出了一颗反常识的「深水炸弹」:他们抛弃了液冷,抛弃了昂贵的HBM显存,甚至抛弃了「通用计算」,选择了一种最粗暴、最狂野的物理美学:直接把大模型焊死在芯片里!
今天是大年初六,年还没过完。但有一个新闻却淹没在各种消息中。
这可能是今年最重要的AI新闻,但现在依然还没什么人聊!
这两天,一家成立不到三年的多伦多芯片公司Taalas扔下了一颗核弹:
他们绕开了所有热门概念,直接把AI大模型,物理焊死在芯片里!

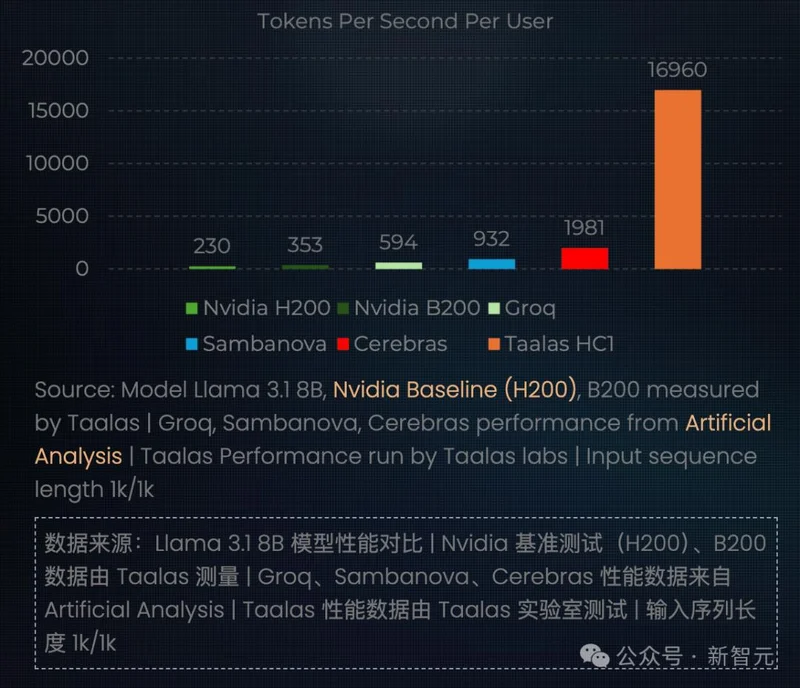
这家公司开发的HC1芯片,运行Llama 3.1 8B的速度达到了极度恐怖的17,000tokens/秒。
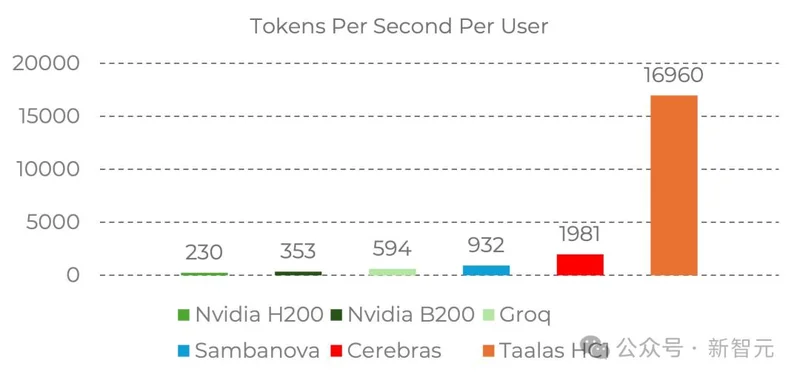
作为对比,目前业界最快Cerebras跑同等模型,速度也不过两千。
Taalas HC1硬生生将速度拔高了将近10倍!
而和英伟达最先进B200,提高了近50倍!

他们还上线了一个体验网站:chatjimmy.ai
这个AI的速度有多离谱呢?可以看看下面的速度。
这个AI不是在回复,而是直接未卜先知把答案砸在你的脸上。
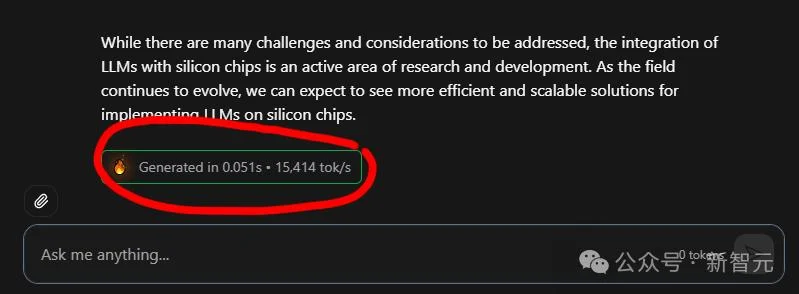
这还不算完,除了「光速」输出Token以外。
Taalas如何解决散热和传输速度问题?
他们交出的答卷是:抛弃液冷!抛弃HBM显存!
因为没有复杂的存储层级,HC1的成本只有传统方案的1/20,功耗更是直接缩减到1/10,十张卡加起来仅仅需要2.5千瓦的空气冷却。

官方博客:https://taalas.com/the-path-to-ubiquitous-ai/
在这块主打「复古暴力」的芯片里,它出厂时的命运就被永远锁死——它的晶体管只为Llama 3.1 8B的权重而生,这辈子只能跑这一个模型。

一时间,X上彻底炸锅了!
「等待LLM思考」的时代宣告终结。
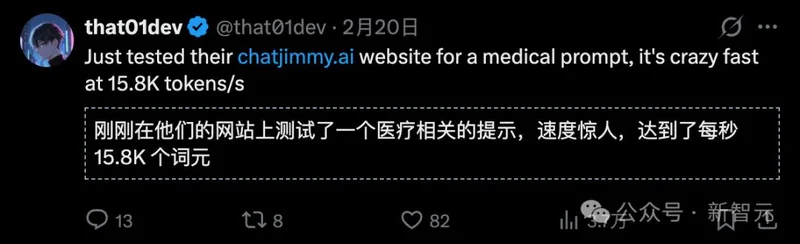
有测试者满脸震撼:
「你敲下回车的瞬间,答案就像预谋已久一样扑在屏幕上,那根本不是秒回,那是啪地一下砸你脸上!」

有网友发出了绝望的哀叹:「人类该怎么跟得上这种速度?」
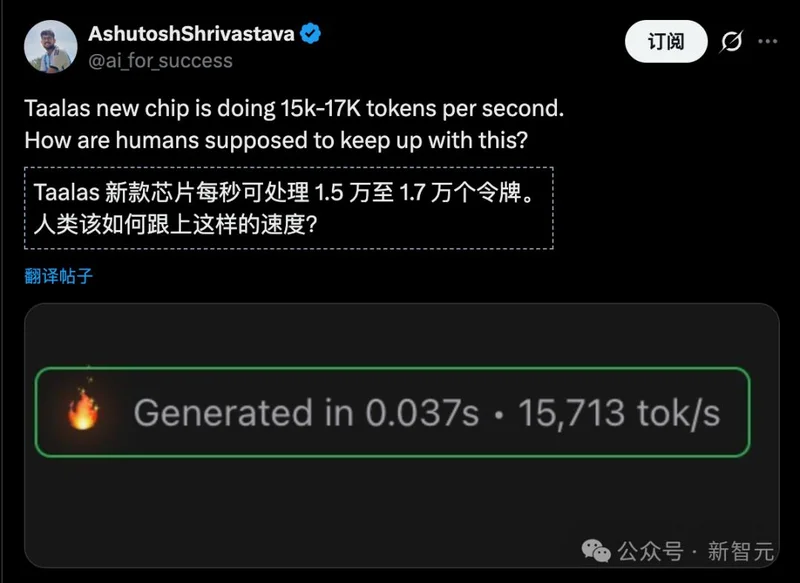
另一位网友的回答则更加冷酷:「尊敬的先生,我们不可能跟得上。」
但反方意见同样明确。
首先就是,虽然速度达到「光速」,但是小模型带来的幻觉问题无法避免。
甚至无法正确计算简单的加减乘除。

而且按照现在的模型的迭代速度。
在一个物理实体上固化一个即将被淘汰的模型,真的有用么?
也有乐观者认为,这可能确实是未来的一种方向,因为这种Token的输出速度,并不是给人类准备的。
而是让智能体之间相互对话使用的。

所以,Taalas这条所谓的物理实体AI之路是否真的能走通?

暴力美学vs极致封印:AI的两条路线之争
要看懂这场「豪赌」的意义,我们必须回顾一下芯片的发展史。
过去三十年,无论是CPU还是GPU,甚至是后来的各种AI加速器,整个硅谷都在疯狂追求同一件事:「造一个通用的计算平台」。
我们在造一个巨大的舞台,然后让不同的软件在上面跳舞。
这就形成了一个绝对的物理硬边界:「内存墙」。
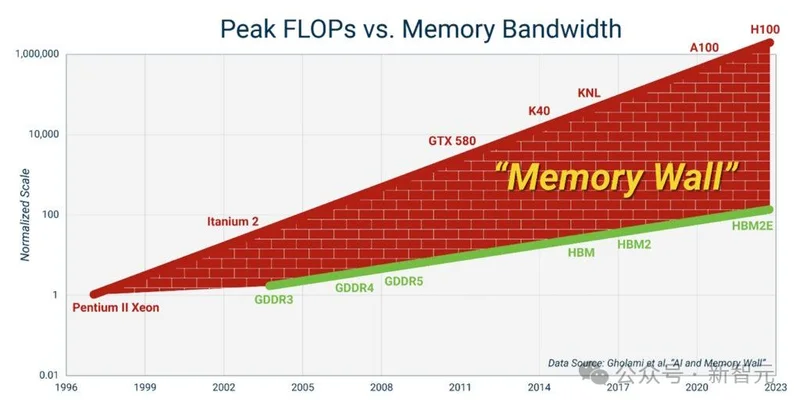
内存墙通常是指处理器速度和内存带宽之间不断扩大的差距
当模型膨胀到几百亿、上千亿参数,你为了算一次乘法,每次都要把海量数据从显存搬到计算单元。
这个「搬砖」过程消耗的能量和时间,早就远远超过了计算本身。
Taalas团队的思路简直是「反向升级」:
既然这个舞台每天都只演《罗密欧与朱丽叶》,我们为什么要费劲巴拉地每天搬布景?直接把布景用水泥砌死在台上不就行了!
在这块HC1芯片里,模型的每一个权重,都对应着芯片上特定的晶体管。

矩阵乘法根本不需要软件去调度,而是通过物理电路的电流直接完成!
你可以把传统的GPU理解为「交响乐团现场演奏」,每次运行都要调配乐手、看曲谱、听指挥;
那么Taalas的做法就是直接刻了一张「黑胶唱片」。
你把Llama模型录死在磁带上,插上电就能播,而且是以一种摧枯拉朽的倍速在狂飙。
但,一切命运的馈赠,都在暗中早就标好了价格!
这也意味着,只要这块芯片一出厂,它的命运就已经被彻底锁死。
它无法微调,无法更换模型,更无法升级。
如果明年Meta发布了Llama 4,或者你发现这个8B模型在特定业务里太卡智商,这块满载尖端科技的硅片,瞬间就会沦为精美的电子垃圾。
在这个所有巨头都在拼命炫耀自家新模型多聪明的时代,主动把自己锁死在一个固定的历史版本上,这到底是逆天改命,还是饮鸩止渴?
路线大分裂与人脑的奇妙隐喻
事实上,这种极尽专用的思路,背后牵扯出的是一场硅谷顶级大佬的路线大决裂。
Taalas的CEO Ljubisa Bajic曾在AMD、英伟达担任骨干架构师,也是明星AI芯片公司Tenstorrent的创始人。

2022年,「芯片之神」Jim Keller(「硅仙人」)加入Tenstorrent,Jim Keller 不仅为该公司提供了第一笔资金,后来更直接加入公司担任CTO,并于2023年与Ljubisa Bajic互换角色出任CEO。

Ljubisa在2023年4月宣布从Tenstorrent的日常管理岗位「退休」并转任顾问,其实是为了追求一个更激进、更极端的计算梦想。
他随后创办了新公司Taalas。
Jim Keller的毕生信仰,是做一个通用的、可编程的、软件友好的完美平台。
扩展阅读:英伟达亲手终结CUDA「护城河」?传奇芯片架构师引发争议

而Ljubisa则决绝地走向了另一个极端——
绝对的极繁固化,换取绝对的极简自由。
对于这种把AI模型做成ASIC(专用集成电路)的做法,网上的评价两极分化。
有人嘲讽「流片贵得吓人,模型一更新旧卡就炸死路一条」,但也有极其敏锐的观察者,将它与人类大脑的运行机制,产生了深度的共振。
X上一条高赞评论直指灵魂:
「哈佛和谷歌耗尽资源,花了十年时间,才勉强绘制出1立方毫米、比米粒还小的人脑图谱。这背后的数学复杂度和能效比,足以让地球上所有的AI实验室集体汗颜。」
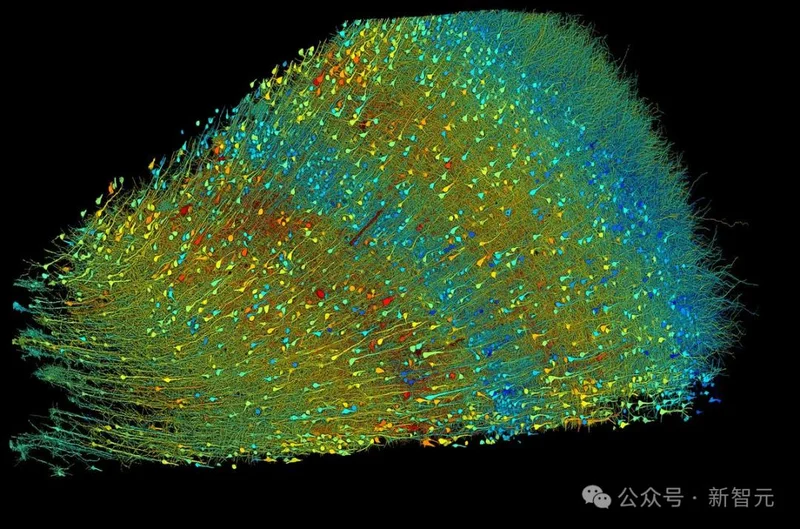
人类大脑那种不可思议的精密和低功耗,本质上不就是一种长在肉体上的「硬件固化」吗?

且人脑的运算虽然精妙,但光论「生成代码」和「吐词」的速度,可远没有这类新硬件这般快如闪电。

另一位网友的一席话更让人破防:
「其实大部分人类,一辈子也就说一种语言、做着一份固定的职业。
这和大脑里刻死了一个模型有什么区别?」
一语惊醒梦中人。
我们并非在所有的场景里,都需要一个通晓天文地理、能写诗能解微分方程的「全知全能神」。
在海量的垂直场景里——比如一个需要毫秒级响应的语音助手,流水线上的自动化数据标注,甚至是你家里每天只懂避障的扫地机。
它们根本不在乎你是GPT-6还是Claude 5,它们需要的仅仅是像一颗钉子一样,用光速和最低廉的成本,把手头那件事干到极致。
这时候,一个极其便宜、永远不需要换代的「电子牛马」芯片,就足够了。
也许这就是AI走向物理世界的终极两极分化:
一部分化作云端庞大而昂贵的通用神灵;
而另一部分,则被死死刻进硅晶体里,化作数以百亿计的廉价、极速的工匠,渗透进人类生活的每一个毛孔。
Taalas这步险棋,可能成为技术史上一次昂贵而有趣的注脚,但也极有可能,正在砸开一扇用「零延迟」统治未来的大门。
无论怎样,17,000 tokens/秒的凶兽已经出笼。
在绝对的速度和暴力成本面前,传统的AI硬件法则,已经出现了一道刺眼的裂痕。
你认为人类的科技树,应该点在哪里?